Unix (trademarked as UNIX) is a family of multitasking, multi-user computer operating systems that derive from the original AT&T Unix, developed in the 1970s at the Bell Labs research center by Ken Thompson, Dennis Ritchie, and others.
Unix..?
The UNIX operating system is a set of programs that act as a link between the computer and the user.
The computer programs that allocate the system resources and coordinate all the details of the computer's internals is called the operating system or kernel.
Users communicate with the kernel through a program known as the shell. The shell is a command line interpreter; it translates commands entered by the user and converts them into a language that is understood by the kernel.
Few Characteristics Shared by Unix:-
1. Simplicity
2. Focus
3. Reusable Components
4. Filters
5. Open file formats
6. Flexibility
H/W Requirements:-
--> 80MB Hard Disk
--> Atleast 4MB of RAM on a 16-bit microprocessor
--> 4/8/16 port controller card
In 80MB Hard Disk --> 40MB used by unix Operating System
--> 10-20MB as Swap Space
--> 0.75 to 1MB for terminal
--> Unix requires amount of human support
Sailent Features of unix:-
Multiuser Capability - In Multi user system, the same computer resources like HD, Memory etc,. are accessible to many users
Dumb terminals - these terminals consist of a keyboard and a display unit with no memory or disk of its own
Terminal Emulation - The S/W that makes PC work like dumb terminal is call terminal emulation, eg: VTERM and XTALK are popularly used such S/W
Dial-in Terminals - These terminals use telephone lines to connect with host machine these uses modem
Multitaksing - It is capable of carrying at more than one job at the same time. In MS-Dos, multitasking is called serial multitasking
Communication
Security - It allows sharing of data,but not indiscriminality
- Read, Write and Excute Permissions
- File Encryption
- Assigning Password and Login
Portability - unix is H/W transperancy. Infact it is almost written entirely in C.
Types of Shell:-
Bourne Shell
C Shell
Korn Shell
Command Syntax:-
Command [options] [argu], Note: Option is generally precided with hyphen(-)
Data Streams
In computer programming, standard streams are preconnected input and output communication ... Unix eliminated this complexity with the concept of a data stream: an ordered sequence of data bytes which can be read until the end of file.
"stdin" --> used to input to any program or process, input streams: <, 0<
"stdout" --> output to any program or process, output streams: >, 1>
"stderr" --> error thrown by any program or process, error streams: 2>
A Stream is a sequence of data bytes used to channel data into or from program or process.
eg:- input:- $cat < file1
output:- $cat > file1
error:- $cat < file1 if file is not available
Shell Metacharacters/ wild card pattern matching
? --> used to match any single charater
* --> used to match zero or many characters
[xyz] --> used to match either x or y or z
[!xyz] --> used to match any one character except x,y,z
[s-z] --> used to match any character with in a range
3. Text Processing - These commands are used to process the text
a. wc Syn:- $wc [-lwc] filename --used to display total no of lines,words and characters in any data
Options:- -l -->No of lines
-w -->No of words
-c -->No of characters
b. Pipe sym: | --> used to send data from 1st command to 2nd command
eg: $ls|wc -l
c.head --used to display a set of lines of the given data from start
Syn: $head [-n] file_name
d. tail --used to display a set of lines of the given data from last
Syn: $tail [-n/+n] file_name
Options -n: No of positions from last
+n: No of positions from nth position to last
e. cut --used to retrieve specific fields or characters from the data
--used on O/P of some other cmd or file
Syn: $cmd -o/p|cut [Options..]
eg: cut [options...] file
options: -c: character set
-f: field set
-d: delimeter for field set
f. tr --used to translate characters used on o/p of some other command
Syn: $cmd -o/p|tr[Options..] src_charset trgt_charset
g. sort --used to order the data
syn: $sort[options..]file
options: -r used to reverse
-u used to remove duplicate
-n numerical sort
h. grep --used to search a pattern in given data
Syn: $grep[options..] pattern_data
Options: -i ignoring case
-c print only count of no of lines
-v print not containing
^pattern print starting with any pattern
pattern$ print ending with any pattern
File Permissions
File ownership is an important component of UNIX that provides a secure method for storing files. Every file in UNIX has the following attributes/users -
Owner permissions - The owner's permissions determine what actions the owner of the file can perform on the file.
Group permissions - The group's permissions determine what actions a user, who is a member of the group that a file belongs to, can perform on the file.
Other (world) permissions - The permissions for others indicate what action all other users can perform on the file.
While using ls -l command it displays various information related to file permission as follows -
$ls -l /home/amrood
-rwxr-xr-- 1 amrood users 1024 Nov 2 00:10 myfile
drwxr-xr--- 1 amrood users 1024 Nov 2 00:10 mydir
Here first column represents different access mode ie. permission associated with a file or directory.
The permissions are broken into groups of threes, and each position in the group denotes a specific permission, in this order: read (r), write (w), execute (x) The first three characters (2-4) represent the permissions for the file's owner. For example -rwxr-xr-- represents that owner has read (r), write (w) and execute (x) permission.
The second group of three characters (5-7) consists of the permissions for the group to which the file belongs. For example -rwxr-xr-- represents that group has read (r) and execute (x) permission but no write permission.
The last group of three characters (8-10) represents the permissions for everyone else. For example -rwxr-xr-- represents that other world has read (r) only permission.
File Access Modes
The basic building blocks of Unix permissions are the read, write, and execute permissions, which are described below -
1. Read -- Grants the capability to read ie. view the contents of the file.
2. Write --Grants the capability to modify, or remove the content of the file.
3. Execute --User with execute permissions can run a file as a program.
Directory Access Modes
Directory access modes are listed and organized in the same manner as any other file. There are a few differences to be mentioned:
1. Read --Access to a directory means that the user can read the contents. The user can look at the filenames inside the directory.
2. Write --Access means that the user can add or delete files to the contents of the directory.
3. Execute --Executing a directory doesn't really make a lot of sense so think of this as a traverse permission.
A user must have execute access to the bin directory in order to execute ls or cd command.
Changing Permissions
To change file or directory permissions, you use the chmod (change mode) command. There are two ways to use chmod: symbolic mode and absolute mode.
Using chmod in Symbolic Mode
The easiest way for a beginner to modify file or directory permissions is to use the symbolic mode. With symbolic permissions you can add, delete, or specify the permission set you want by using the operators in the following table.
Syn:- chmod [ugoa][+-=][rwx] filename
Using chmod in Absolute Mode
Syn:- chmod [0-7][0-7][0-7] filename
4. File Utility
File Utility is to find the file in unix system
Syn:- find [path][criteria][action] filename
Options:
[path] can be provided as follows
. current directory
.. parent directory
~ default home directory
Any absoolute path
Any relative path
[criteria] can be given like this
-name used to find using name of file
-type used to find using type of file
-links used to find using links of file
-perm used to find using perm of file
-size used to find using size of the file
[action] used to perform following action on file after searching
-print used to print the file
-exec used to find and execute the command
-ok used to find and execute the command interactively
5.Compression Utilities - used to compress and decompress the files or directories
a. gzip -used to compress and decompress the files
syn:- $gzip file1,file1,file3... to compress the file
Syn:- $gzip -d file1 to de-compress the file
b. zcat -used to view compressed file
c. zmore -used to view compressed file page-wise
d. gunzip -used to decompress
f. tar -used to archieve the files/directories
g. tring -used to backup the directory/directories
6. Process Commands
Whenever you issue a command in UNIX, it creates, or starts, a new process. When you tried out the ls command to list directory contents, you started a process. A process, in simple terms, is an instance of a running program.
The operating system tracks processes through a five digit ID number known as the pid or process ID . Each process in the system has a unique pid.
Pids eventually repeat because all the possible numbers are used up and the next pid rolls or starts over. At any one time, no two processes with the same pid
exist in the system because it is the pid that UNIX uses to track each process.
Starting a Process
When you start a process (run a command), there are two ways you can run it -
Foreground Processes
Background Processes
a. ps --used to list all the processes
Syn:- $ps will return the processes which are running our own process
Syn:- $ps -f will return the processes with more information
b. sleep --used to provide the delay of the process
c. fg --used to bring background process to foreground
d. kill --used to kill the process
e. prstat --use to see all the processes with memory details
Syn:- prstat <interval><count> -p <pid>
Operators in Unix
There are various operators supported by each shell. Our tutorial is based on default shell (Bourne) so we are going to cover all the important Bourne Shell operators in the tutorial.
There are following operators which we are going to discuss -
Arithmetic Operators.
Relational Operators.
Boolean Operators.
String Operators.
File Test Operators.
Numeric Operators.
The Bourne shell didn't originally have any mechanism to perform simple arithmetic but it uses external programs, either awk or the must simpler program expr.
Here is simple example to add two numbers -
#!/bin/sh
val=`expr 2 + 2`
echo "Total value : $val"
This would produce following result -
Total value : 4
There are following points to note down -
There must be spaces between operators and expressions for example 2+2 is not correct, where as it should be written as 2 + 2.
Complete expression should be enclosed between ``, called inverted commas.
Relational Operators
-eq "equals to" Syn:$test Value1 -eq Value2
-lt "less than"
-gt "greater than"
-le "less than or equal to"
-ge "greater than or equal to"
-ne "not equals to"
Arithmetic Operators
+ --Addition Syn:- expr $a + $b
- --Subtraction
* --Multiplication
/ --Division
% --Modulus
= --Assignment
== --Equality
!= --Not Equality
Boolean Operators
! --Logical negation
-o --Logical OR
-a --Logical AND
&& --Conditional and operator
|| --Conditional OR operator
String Operators
= --String equals to or not
!= --String not equals
-z --given string operand size is zero. If it is zero length then it returns true.
-n --given string operand size is non-zero. If it is non-zero length then it returns true.
str --if str is not the empty string. If it is empty then it returns false.
File Test Operators
-b --if file is a block special file if yes then condition becomes true.
-c --if file is a character special file if yes then condition becomes true.
-d --if file is a directory if yes then condition becomes true.
-f --if file is an ordinary file as opposed to a directory or special file if yes then condition becomes true.
-g --if file has its set group ID (SGID) bit set if yes then condition becomes true.
-k --if file has its sticky bit set if yes then condition becomes true.
-p --if file is a named pipe if yes then condition becomes true.
-t --if file descriptor is open and associated with a terminal if yes then condition becomes true.
-u --if file has its set user id (SUID) bit set if yes then condition becomes true.
-r --if file is readable if yes then condition becomes true.
-w --if file is writable if yes then condition becomes true.
-x --if file is execute if yes then condition becomes true.
-s --if file has size greater than 0 if yes then condition becomes true.
-e --if file has size greater than 0 if yes then condition becomes true.
Program Contructs
Selectional -- If and Case
Iterational -- for, while and until
If Statement
Syn:- if <control command>
then
<commands>
fi
if-else Statement
Syn:- if <control command>
then
<commands>
else
<commands>
fi
else-if statement
Syn:- if <control command>
then
<commands>
elif <control command>
then
<commands>
fi
case statement
Syn:- case value in
c1) commands ;;
c2) commands ;;
c3) commands ;;
...
...
esac
Note: value can be any expression also
for loop statement
Syn:- for variable_name in v1,v2,v3,v4...vn
do
<commands>
done
While loop statement
Syn:- while <control commands>
do
<commands>
done
until loop statment
Syn:- until <control commands>
do
<commands>
done
Unix..?
The UNIX operating system is a set of programs that act as a link between the computer and the user.
The computer programs that allocate the system resources and coordinate all the details of the computer's internals is called the operating system or kernel.
Users communicate with the kernel through a program known as the shell. The shell is a command line interpreter; it translates commands entered by the user and converts them into a language that is understood by the kernel.
Few Characteristics Shared by Unix:-
1. Simplicity
2. Focus
3. Reusable Components
4. Filters
5. Open file formats
6. Flexibility
H/W Requirements:-
--> 80MB Hard Disk
--> Atleast 4MB of RAM on a 16-bit microprocessor
--> 4/8/16 port controller card
In 80MB Hard Disk --> 40MB used by unix Operating System
--> 10-20MB as Swap Space
--> 0.75 to 1MB for terminal
--> Unix requires amount of human support
Sailent Features of unix:-
Multiuser Capability - In Multi user system, the same computer resources like HD, Memory etc,. are accessible to many users
Dumb terminals - these terminals consist of a keyboard and a display unit with no memory or disk of its own
Terminal Emulation - The S/W that makes PC work like dumb terminal is call terminal emulation, eg: VTERM and XTALK are popularly used such S/W
Dial-in Terminals - These terminals use telephone lines to connect with host machine these uses modem
Multitaksing - It is capable of carrying at more than one job at the same time. In MS-Dos, multitasking is called serial multitasking
Communication
Security - It allows sharing of data,but not indiscriminality
- Read, Write and Excute Permissions
- File Encryption
- Assigning Password and Login
Portability - unix is H/W transperancy. Infact it is almost written entirely in C.
Types of Shell:-
Bourne Shell
C Shell
Korn Shell
Command Syntax:-
Command [options] [argu], Note: Option is generally precided with hyphen(-)
 |
| Unix Architecture |
 |
| File Hierarchy |
Unix Command Categories - Basics with examples
1. General Purpose Commands
a. Clear Syn:- $clear
b. WHO Syn:- $WHO[argu]
c. Date Syn:- $date[+format]
d. Cal Syn:- $cal[argu]
e. Type Syn:- $type command_name
f. PWB Syn:- $pwd
g. MAN Syn:- $man
2. File and Directory Commands
a. ls Syn:- $ls [options] dir/file_name
Options:- -a hidden files
-l display list in long format
-r list recursively
-i list with inode values
b. touch Syn:- $touch file1[file2...] -- used to create empty files
c. cat Syn:- Create File: $cat >filename
Display File: $cat filename
Append File: $cat >>filename
Used to create files and save content in file, Display files and append the files with new extra content
d. more Syn:- $more -- used to display/prints content in page wise
e. mkdir Syn:- $mkdir dir_name --used to create directories
f. cd Syn:- $cd dir_name --used to change directory
g. rmdir Syn:- $rmdir dir_name --used to remove directory
h. rm Syn:- $rm file/dir_name
$rm file1[file2..] --remove all the files
$rm -r file1 --remove file recur
$rm -i file --remove file interactively
i. mv Syn:- $mv src trgt --used to rename file name or move files from src to trgt
j. cp Syn:- $cp src trgt --used to copy files from src to trgt
k. ln Syn:- $ln -s src trgt --makes soft or symbolic links between files.
$ln src trgt --used to create hard links between files
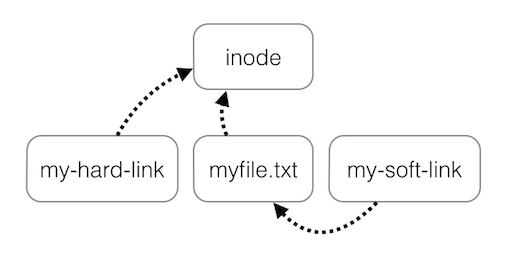 |
| Hard link and Soft link |
Hard Link
|
Soft Link
|
Inode number is same for original and link
file
|
Inode number is different for the original
and link file
|
link will be valid if original is deleted
|
link is not valid if original is deleted
|
cannot be established for directories
|
can be established for the directories
|
for every hard link created, value of the
link field is incremented by 1 for original as well as link file
|
Link field value would be 1 for link file
and no change in link field value of original field
|
Data Streams
In computer programming, standard streams are preconnected input and output communication ... Unix eliminated this complexity with the concept of a data stream: an ordered sequence of data bytes which can be read until the end of file.
"stdin" --> used to input to any program or process, input streams: <, 0<
"stdout" --> output to any program or process, output streams: >, 1>
"stderr" --> error thrown by any program or process, error streams: 2>
A Stream is a sequence of data bytes used to channel data into or from program or process.
eg:- input:- $cat < file1
output:- $cat > file1
error:- $cat < file1 if file is not available
Shell Metacharacters/ wild card pattern matching
? --> used to match any single charater
* --> used to match zero or many characters
[xyz] --> used to match either x or y or z
[!xyz] --> used to match any one character except x,y,z
[s-z] --> used to match any character with in a range
3. Text Processing - These commands are used to process the text
a. wc Syn:- $wc [-lwc] filename --used to display total no of lines,words and characters in any data
Options:- -l -->No of lines
-w -->No of words
-c -->No of characters
b. Pipe sym: | --> used to send data from 1st command to 2nd command
eg: $ls|wc -l
c.head --used to display a set of lines of the given data from start
Syn: $head [-n] file_name
d. tail --used to display a set of lines of the given data from last
Syn: $tail [-n/+n] file_name
Options -n: No of positions from last
+n: No of positions from nth position to last
e. cut --used to retrieve specific fields or characters from the data
--used on O/P of some other cmd or file
Syn: $cmd -o/p|cut [Options..]
eg: cut [options...] file
options: -c: character set
-f: field set
-d: delimeter for field set
f. tr --used to translate characters used on o/p of some other command
Syn: $cmd -o/p|tr[Options..] src_charset trgt_charset
g. sort --used to order the data
syn: $sort[options..]file
options: -r used to reverse
-u used to remove duplicate
-n numerical sort
h. grep --used to search a pattern in given data
Syn: $grep[options..] pattern_data
Options: -i ignoring case
-c print only count of no of lines
-v print not containing
^pattern print starting with any pattern
pattern$ print ending with any pattern
File Permissions
File ownership is an important component of UNIX that provides a secure method for storing files. Every file in UNIX has the following attributes/users -
Owner permissions - The owner's permissions determine what actions the owner of the file can perform on the file.
Group permissions - The group's permissions determine what actions a user, who is a member of the group that a file belongs to, can perform on the file.
Other (world) permissions - The permissions for others indicate what action all other users can perform on the file.
While using ls -l command it displays various information related to file permission as follows -
$ls -l /home/amrood
-rwxr-xr-- 1 amrood users 1024 Nov 2 00:10 myfile
drwxr-xr--- 1 amrood users 1024 Nov 2 00:10 mydir
Here first column represents different access mode ie. permission associated with a file or directory.
The permissions are broken into groups of threes, and each position in the group denotes a specific permission, in this order: read (r), write (w), execute (x) The first three characters (2-4) represent the permissions for the file's owner. For example -rwxr-xr-- represents that owner has read (r), write (w) and execute (x) permission.
The second group of three characters (5-7) consists of the permissions for the group to which the file belongs. For example -rwxr-xr-- represents that group has read (r) and execute (x) permission but no write permission.
The last group of three characters (8-10) represents the permissions for everyone else. For example -rwxr-xr-- represents that other world has read (r) only permission.
File Access Modes
The basic building blocks of Unix permissions are the read, write, and execute permissions, which are described below -
1. Read -- Grants the capability to read ie. view the contents of the file.
2. Write --Grants the capability to modify, or remove the content of the file.
3. Execute --User with execute permissions can run a file as a program.
Directory Access Modes
Directory access modes are listed and organized in the same manner as any other file. There are a few differences to be mentioned:
1. Read --Access to a directory means that the user can read the contents. The user can look at the filenames inside the directory.
2. Write --Access means that the user can add or delete files to the contents of the directory.
3. Execute --Executing a directory doesn't really make a lot of sense so think of this as a traverse permission.
A user must have execute access to the bin directory in order to execute ls or cd command.
Changing Permissions
To change file or directory permissions, you use the chmod (change mode) command. There are two ways to use chmod: symbolic mode and absolute mode.
Using chmod in Symbolic Mode
The easiest way for a beginner to modify file or directory permissions is to use the symbolic mode. With symbolic permissions you can add, delete, or specify the permission set you want by using the operators in the following table.
Syn:- chmod [ugoa][+-=][rwx] filename
Using chmod in Absolute Mode
Syn:- chmod [0-7][0-7][0-7] filename
4. File Utility
File Utility is to find the file in unix system
Syn:- find [path][criteria][action] filename
Options:
[path] can be provided as follows
. current directory
.. parent directory
~ default home directory
Any absoolute path
Any relative path
[criteria] can be given like this
-name used to find using name of file
-type used to find using type of file
-links used to find using links of file
-perm used to find using perm of file
-size used to find using size of the file
[action] used to perform following action on file after searching
-print used to print the file
-exec used to find and execute the command
-ok used to find and execute the command interactively
5.Compression Utilities - used to compress and decompress the files or directories
a. gzip -used to compress and decompress the files
syn:- $gzip file1,file1,file3... to compress the file
Syn:- $gzip -d file1 to de-compress the file
b. zcat -used to view compressed file
c. zmore -used to view compressed file page-wise
d. gunzip -used to decompress
f. tar -used to archieve the files/directories
g. tring -used to backup the directory/directories
6. Process Commands
Whenever you issue a command in UNIX, it creates, or starts, a new process. When you tried out the ls command to list directory contents, you started a process. A process, in simple terms, is an instance of a running program.
The operating system tracks processes through a five digit ID number known as the pid or process ID . Each process in the system has a unique pid.
Pids eventually repeat because all the possible numbers are used up and the next pid rolls or starts over. At any one time, no two processes with the same pid
exist in the system because it is the pid that UNIX uses to track each process.
Starting a Process
When you start a process (run a command), there are two ways you can run it -
Foreground Processes
Background Processes
a. ps --used to list all the processes
Syn:- $ps will return the processes which are running our own process
Syn:- $ps -f will return the processes with more information
b. sleep --used to provide the delay of the process
c. fg --used to bring background process to foreground
d. kill --used to kill the process
e. prstat --use to see all the processes with memory details
Syn:- prstat <interval><count> -p <pid>
Operators in Unix
There are various operators supported by each shell. Our tutorial is based on default shell (Bourne) so we are going to cover all the important Bourne Shell operators in the tutorial.
There are following operators which we are going to discuss -
Arithmetic Operators.
Relational Operators.
Boolean Operators.
String Operators.
File Test Operators.
Numeric Operators.
The Bourne shell didn't originally have any mechanism to perform simple arithmetic but it uses external programs, either awk or the must simpler program expr.
Here is simple example to add two numbers -
#!/bin/sh
val=`expr 2 + 2`
echo "Total value : $val"
This would produce following result -
Total value : 4
There are following points to note down -
There must be spaces between operators and expressions for example 2+2 is not correct, where as it should be written as 2 + 2.
Complete expression should be enclosed between ``, called inverted commas.
Relational Operators
-eq "equals to" Syn:$test Value1 -eq Value2
-lt "less than"
-gt "greater than"
-le "less than or equal to"
-ge "greater than or equal to"
-ne "not equals to"
Arithmetic Operators
+ --Addition Syn:- expr $a + $b
- --Subtraction
* --Multiplication
/ --Division
% --Modulus
= --Assignment
== --Equality
!= --Not Equality
Boolean Operators
! --Logical negation
-o --Logical OR
-a --Logical AND
&& --Conditional and operator
|| --Conditional OR operator
String Operators
= --String equals to or not
!= --String not equals
-z --given string operand size is zero. If it is zero length then it returns true.
-n --given string operand size is non-zero. If it is non-zero length then it returns true.
str --if str is not the empty string. If it is empty then it returns false.
File Test Operators
-b --if file is a block special file if yes then condition becomes true.
-c --if file is a character special file if yes then condition becomes true.
-d --if file is a directory if yes then condition becomes true.
-f --if file is an ordinary file as opposed to a directory or special file if yes then condition becomes true.
-g --if file has its set group ID (SGID) bit set if yes then condition becomes true.
-k --if file has its sticky bit set if yes then condition becomes true.
-p --if file is a named pipe if yes then condition becomes true.
-t --if file descriptor is open and associated with a terminal if yes then condition becomes true.
-u --if file has its set user id (SUID) bit set if yes then condition becomes true.
-r --if file is readable if yes then condition becomes true.
-w --if file is writable if yes then condition becomes true.
-x --if file is execute if yes then condition becomes true.
-s --if file has size greater than 0 if yes then condition becomes true.
-e --if file has size greater than 0 if yes then condition becomes true.
Program Contructs
Selectional -- If and Case
Iterational -- for, while and until
If Statement
Syn:- if <control command>
then
<commands>
fi
if-else Statement
Syn:- if <control command>
then
<commands>
else
<commands>
fi
else-if statement
Syn:- if <control command>
then
<commands>
elif <control command>
then
<commands>
fi
case statement
Syn:- case value in
c1) commands ;;
c2) commands ;;
c3) commands ;;
...
...
esac
Note: value can be any expression also
for loop statement
Syn:- for variable_name in v1,v2,v3,v4...vn
do
<commands>
done
While loop statement
Syn:- while <control commands>
do
<commands>
done
until loop statment
Syn:- until <control commands>
do
<commands>
done